Footstep Sound Effect Synthesis Using Variational Auto-Encoder (VAE) Architecture
2021-07-07
MMI727 Deep Learning: Methods and Applications
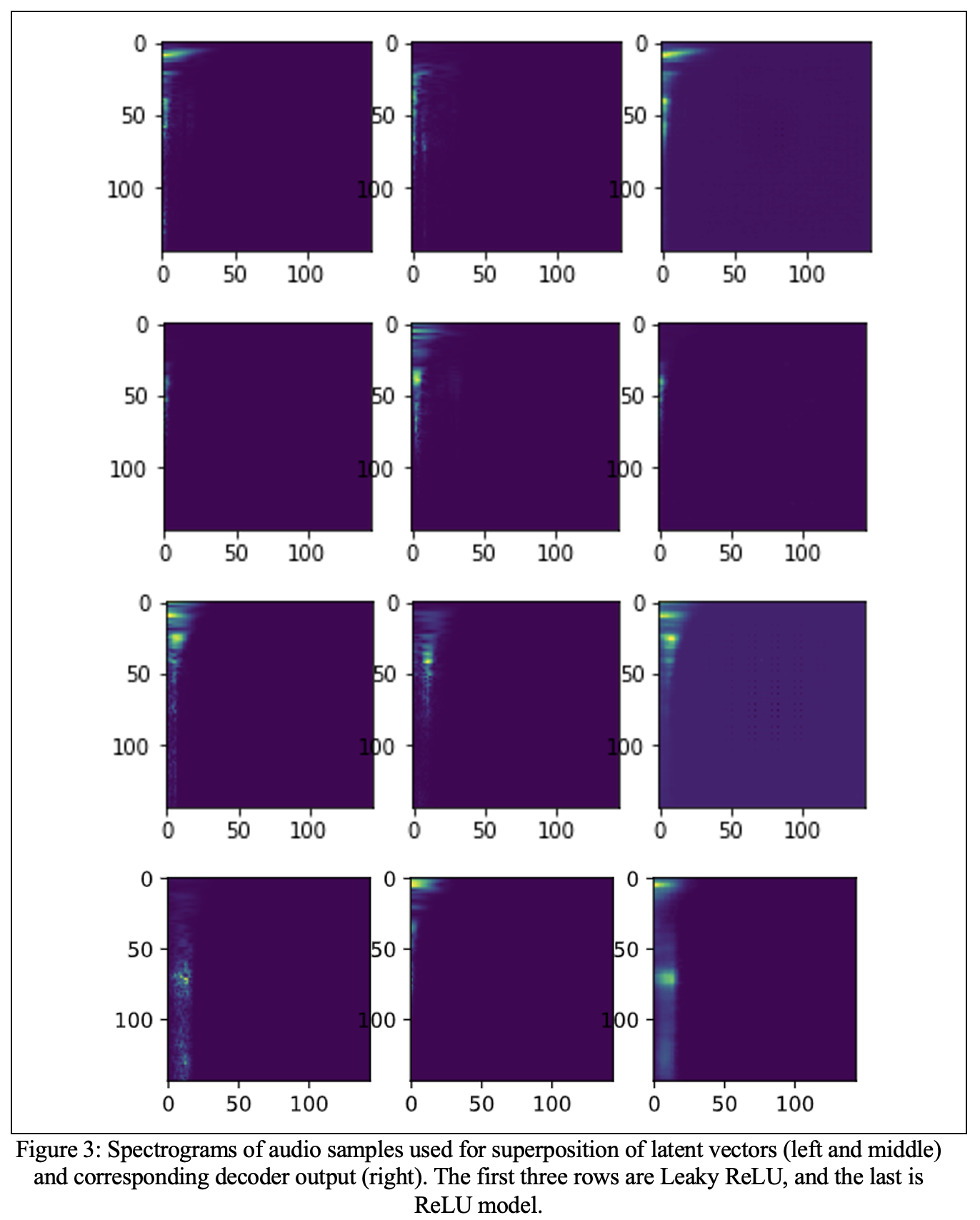
Using Variational Auto-Encoders, we reconstruct the existing and generate synthetic sounds. Constant-Q transform is used for feature extraction from audio data. We train our model for 50 epochs with spectrograms of size 144x144 using this transform, corresponding to 1.67 s of audio sampled at 44100 Hz. Two different strategies are used for sound generation: using randomly generated latent vectors and superposing the latent vectors of various sounds. We explore the generative and reconstructive abilities of this model using a footstep audio sample library.
Practical applications for this project concern a niche but a wide community of sound production people – if we were only to talk about developers in a world of mobile apps. The sounds these producers create are everywhere to be heard but not to be realized most of the time. Sound is an interesting phenomenon to discuss in terms of artificiality – the most successful designs are designed to go unnoticed.
Dataset
BOOM Library - Virtual Foley Artist - Footsteps
•30,000+ audio clips
•<2 s duration
•96 kHz / 24-bit PCM
•Clean, professional recordings
•Converted to: 44.1 kHz, clipped/padded to 1.67 s
•Floor material, shoe type, decorators, action, et cetera
Method
The project can be disassembled into three main stages: extracting spectrograms from dataset, training model, generating new spectrogram samples, inverse transforming spectrogram into an audio waveform.
Spectrogram extraction is done using Constant-Q transform abilities of librosa, a Python library focused on sound. All sounds are either clipped or zero-padded to complete a 1.67 s time frame at 44.1 kHz. Transform outputs 16 bins per octave (see: octave in music) and 9 octaves, resulting in 144 bins for the frequency bins axis. Inverse transforming is done using the same parameters.
The model has a VAE architecture. The encoder features convolutional layers to project the input spectrogram onto a compressed space, i.e., latent space, outputting a position vector, i.e., latent vector. The decoder features transpose convolution layers that decompress this vector, outputting a reconstructed spectrogram.
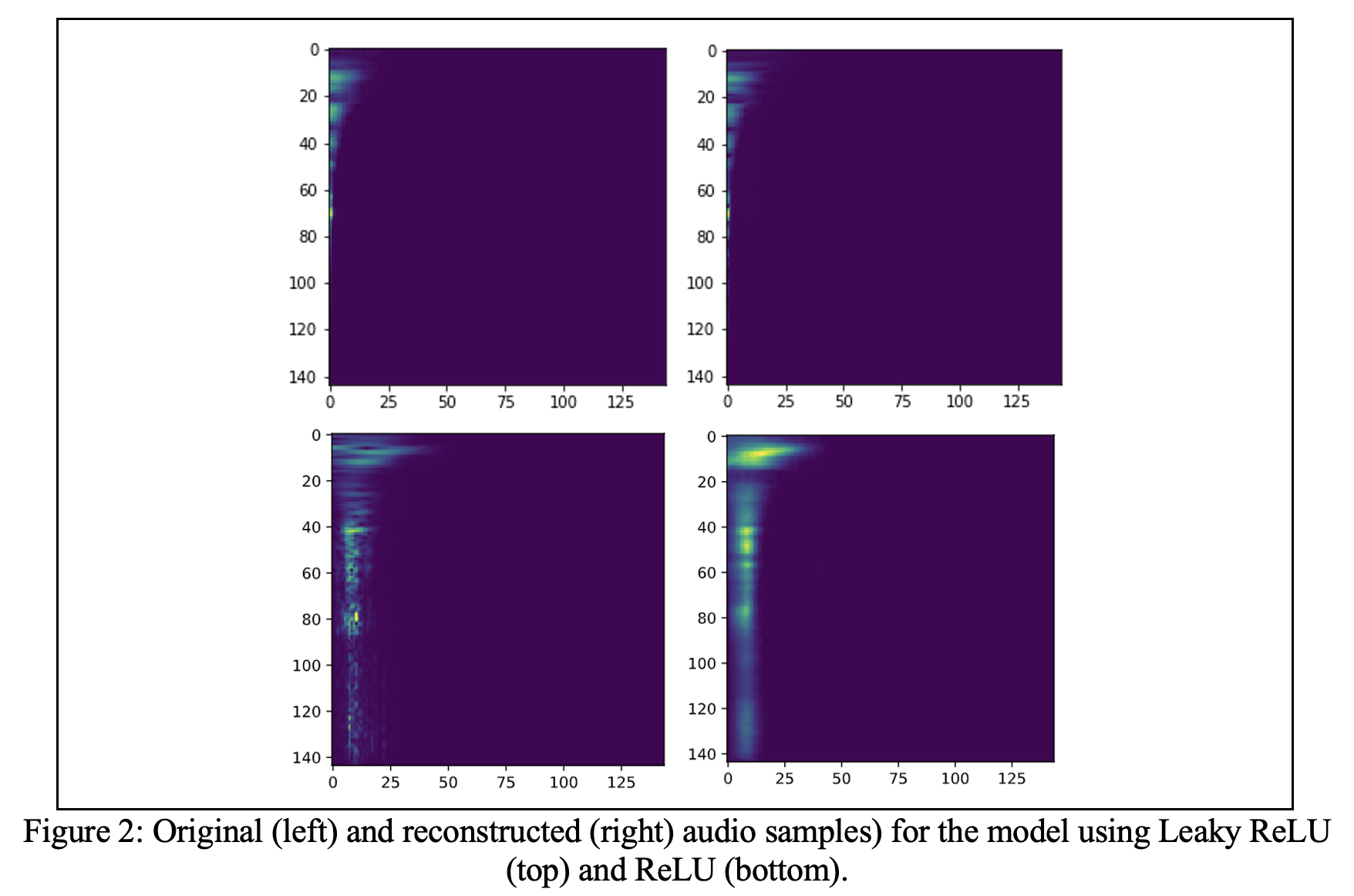
The model is trained on Tesla P100 16 GB GPU for about 20 min for 50 epochs disregarding memory operations, et cetera. The learning rate is 0.001. The best loss value is 50, and the best validation loss value is 25, each approximately. Two variations of the model are used: using Leaky ReLU and ReLU. Comparison is omitted where too little difference is observed.
In summary, reconstruction is satisfactory compared to the spectrograms extracted from original audio samples. Reconstructed sounds are not and simply cannot be compared here in terms of perception and realism. Nonetheless, these sounds, which are also reconstructed from spectrograms using inverse CQT, are unsatisfactory in mentioned terms compared to the original signals. Investigating this problem, we found that although the similarity between the original sound file and the reconstructed one is low, if we compare the synthesized with the reconstruction from the original sound file’s spectrogram, the similarity is very high.
Problems
The main reason for this problem hid in plain sight for a long time. It is found that the Python library we use, librosa, actually uses an old implementation [5] of CQT, which is not invertible and incomprehensive in nature, and better used as a visualization tool than a training data for machine learning. Invertible CQT uses non-stationary Gabor frames, as explained in [6].
There is another successful Python library for similar operations, named essentia, from Music Technology Group at University Pompeu Fabra, Spain. This library, indeed, implements invertible CQT using non-stationary Gabor frames by referencing [7]. However, another problem occurs here, which is, indeed, a special case mentioned in [6], called the hard case, which is not reliably working yet in the date this paper is written.


References
[1] F. Roche, T. Hueber, S. Limier, and L. Girin, ‘Autoencoders for music sound modeling: a comparison of linear, shallow, deep, recurrent and variational models’, May 2019, Accessed: Apr. 28, 2021. [Online]. Available: http://arxiv.org/abs/1806.04096.
[2] A. van den Oord et al., ‘WaveNet: A Generative Model for Raw Audio’, ArXiv160903499 Cs, Sep. 2016, Accessed: Apr. 28, 2021. [Online]. Available: http://arxiv.org/abs/1609.03499.
[3] ‘NSynth Super’. https://nsynthsuper.withgoogle.com (accessed Apr. 28, 2021).
[4] M. Frenzel, ‘NeuralFunk - Combining Deep Learning with Sound Design’, Max Frenzel. https://maxfrenzel.com/articles/neuralfunk-combining-deep-learning-with-sound-design (accessed Apr. 28, 2021).
[5] Schoerkhuber, Christian, and Anssi Klapuri. “Constant-Q transform toolbox for music processing.” 7th Sound and Music Computing Conference, Barcelona, Spain. 2010.
[6] Holighaus, N., Dörfler, M., Velasco, G. A., & Grill, T. (2013). A framework for invertible, real-time constant-Q transforms. IEEE Transactions on Audio, Speech, and Language Processing, 21(4), 775-785.
[7] Schörkhuber, C., Klapuri, A., Holighaus, N., & Dörfler, M. (n.d.). A Matlab Toolbox for Efficient Perfect Reconstruction Time-Frequency Transforms with Log-Frequency Resolution.