Footstep Sound Effect Synthesis Using State Space Models (SSM) Architecture
2022-07-01
MMI711 Sequence Models in Multimedia
Footsteps are among the most complex but omnipresent sounds in our daily life and sound effects in multimedia applications. There is a considerable research into understanding the acoustics features making up this sound, and into developing synthesising models for footstep sound effects.
In this project, I experimented with a fairly new architecture called SaShiMi for long-range sequence modeling, which is based on S4 layers making use of state space models theory. Due to many problems encountered making the available time for experimenting very short, the results are actually fall short of expectations. Although there are some good samples resulted using specific training configurations, İ believe there is still a big room left for improvement.
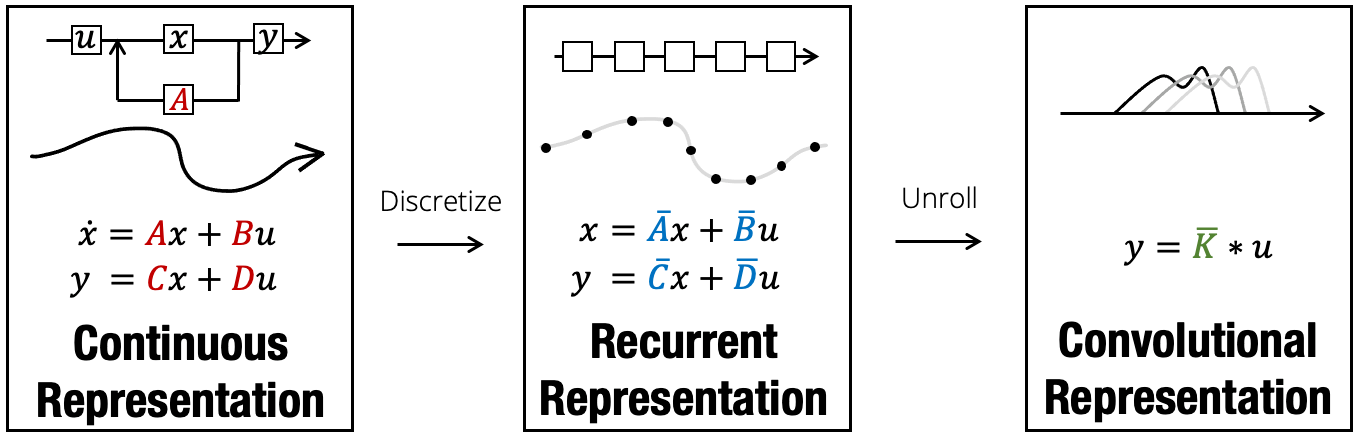

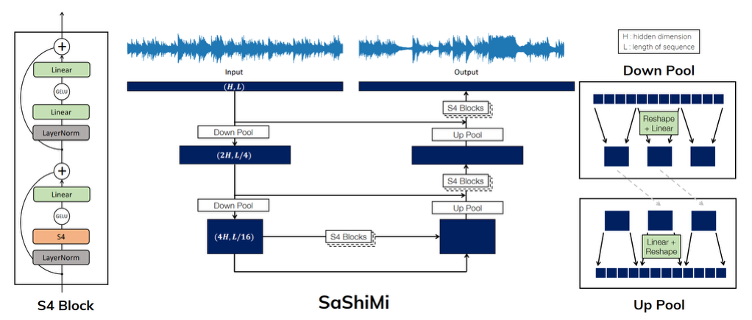
S4 architecture has some differentiating advantages that makes it a good candidate for raw audio modeling:
• It is capable of modeling long range dependencies, making it a good fit for long sequence modeling, like raw audio classification
• It can be computed either as a CNN for efficient parallel training, or an RNN for auto-regressive generation
• It is implicitly based on a continuous-time model, making it suitable for waveform-like signals
An important differentiating property of SaShiMi is that it can train on much longer contexts than existing methods including WaveNet, which is a very successful model that has been for comparison in almost every research related that published after.
I have generated samples unconditioned and conditioned to 10, 20 and 40 ms of audio for each experiment.
In general, less than 25% of the generated samples can be considered useful. This may be the result of relatively small dataset size or the number of epochs trained, which is 100. Overall, the generated samples have non-zero means, though in some samples there are low frequency sine waves observable, meaning the model is able to generate periodic waveform in particular states.
We have observed that checkpoints for best validation loss resulted in the best results for linear and mu-law quantisation. Last checkpoints that are best in training loss does not generate better sounds. This might be due to the overfitting which is observable in the divergence between training and test/validation loss and accuracy.
Unconditional generation creates the most diverse range of sounds, whereas 20 and 40 ms conditional generation samples are, though more narrow in sound characteristics, resulted in sounds with more fidelity.
Results for the experiment with dropout value of 0.5 are mostly silent or unintelligible.